At Seyfarth, I’m not just an attorney—I’m also an ethical hacker and digital forensic expert, and I’m proud to be one of several “attorneys who code” at Seyfarth. Here, we’re passionate about technology, and we routinely seek creative ways to leverage innovations that enhance client services.
I’ve found that one area where emerging technology can make an enormous impact is in the data breach notification assessment space. Specifically, I’ve found that artificial intelligence can power the evaluation of implicated data for personal information like PII and PHI to determine notice requirements in the various implied jurisdictions. While there are many ways to accomplish that evaluation, I wanted to share my experience partnering with Text IQ, a company that builds AI for sensitive information, to power a data breach response in a blind study alongside the traditional document review and coding approach. The result was reduced risk, quicker turnaround time, and cost reduction for Seyfarth’s client.
Casting an Epidemic
The specter of a data breach is an unfortunate reality for anyone that uses a computer. Corporations are obviously large targets, with potentially
thousands of employees doing things on computers. Some of those things are good, and some put the company at risk. Aside from the rapid evolution of attack sophistication and complexity, regulators are also raising the stakes in terms of liability for data breaches and security incidents
Privacy-related data incidents and data breach matters are governed by a proliferating list of statutes: GDPR, CCPA, the New York SHIELD Act, and many others from various states and companies. After they experience a security incident and confirm a data breach, corporations tend to rely on traditional methods to evaluate their exposure and act accordingly. However, these methods are breaking down in the face of burdensome regulatory reporting requirements, often within highly constrained timeframes. One of the shortest of these is GDPR’s “long weekend” reporting period of only 72 hours.
As companies grow, their potential attack surfaces expand accordingly. This is evident in data breach statistics. One data breach tracker estimates that 68 records are stolen every second, thanks of a broad cast of bad actors:

In the wake of a security incident, a decent incident response will generally take some form of the following course:
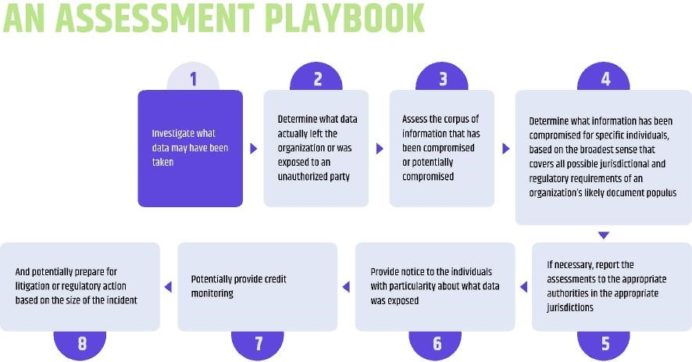
Out with the Old
Relying on traditional methods, this assessment can be a significant challenge for identifying personal information like PII and PHI.
In the status quo, search terms and search expressions may be used to find patterns and PI, and contract attorneys are hired to review the documents and log PI that has been compromised to support the various notice requirements of any jurisdiction that’s implicated.
This traditional model has inherent barriers:
- Understanding the individuals whose PI has been exposed in a dataset is a challenge that calls for an entity view. But the status quo provides only a document view with embedded entities.
- There are myriad types of documents that could contain PI. How does one account for all potential government IDs, tax documents, bank documents, licenses, etc.? Even with complex and comprehensive RegEx, there’s a risk of missing “models” of PI that may exist across the world. As a result, search terms and expressions suffer from inconsistent results and may miss non-obvious data. Unstructured data sources are very difficult to submit to this kind of process.
- Similar to the above, the concept of “a search” as a function, with its roots in techniques like Boolean Search and document retrieval, was never designed to navigate large-scale unstructured data, like the data that is exposed in a breach.
- Search terms yield results that are both over- and under-inclusive, requiring extensive human review. And humans are inefficient and error-prone at poring over large amounts of data. We have inconsistent decision-making across brains, and we also tend to provide typos and other ephemera that introduce incorrect data into PI assessment logs.
Taking the above obstacles into account, Seyfarth’s cybersecurity attorneys have begun leveraging artificial intelligence in more of our processes, including data breach PI assessment. Our Fortune 200 clients in particular have experienced for themselves how using AI can automate rote and low value work, like document review, and augment high value work—lending human subject matter expertise to exercise judgment and give legal advice.
In our first project with Text IQ, we leveraged its AI-powered solution, Text IQ for Legal, to reduce the cost and burden of conducting privilege reviews and generating logs. Subsequently, we used another of its offerings, Text IQ for Privacy, in a Proof of Concept project to identify PI after a client suffered a data breach. To compare Text IQ with traditional document review, we conducted a blind study of human versus machine.
The results speak for themselves:

AI for Data Breach Response
Being an (ethical) hacker of things and naturally curious technologist, I wanted to know more about how it works. There are three innovations that have allowed Text IQ to achieve this kind of accuracy in PI detection.
- Social Linguistic HypergraphTM: Text IQ combines social signals with language signals to do something better than perhaps any other AI company out there: find all traces of an individual in a dataset. Its trained machine learning models can understand meaning on a semantic level (e.g. what meaning is intended), as opposed to merely a lexical level (e.g. what terminology is used). As a result, its AI can detect concepts that capture special category information, like political opinions, genetic data, and race and ethnicity.
- Continuous Learning: Text IQ generates interactive dashboards with automatic PII and PHI linking, powering drill-down analysis and data exploration. The user can override or select highlighted PI in each document, and that feedback is automatically re-ingested into the machine in an iterative process that allows the models to self-improve over time.
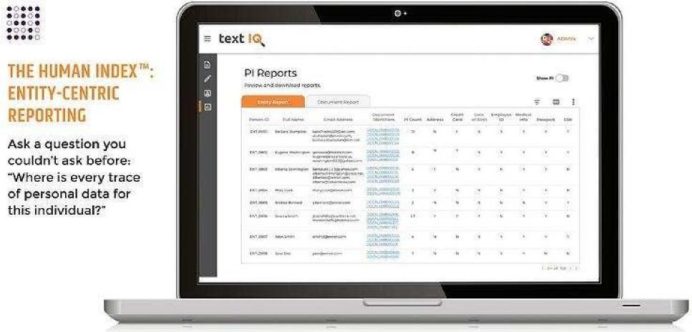
- The Human IndexTM: In addition to document-centric reports, Text IQ provides entity-centric reports with individuals in a column, and all their associated PI traces in rows. This is a new view that allows for a question that we couldn’t ask before: what are all the traces of PII and PHI that exist in this dataset for this individual?
Conclusion
Relying on the status quo to understand large-scale unstructured data is risky. It’s also potentially time-consuming and expensive. Today, AI can completely and reliably automate the low value work of PI identification in document review and reduce risk. It lets cybersecurity practitioners like me better serve our clients.