
Large Language Models (LLMs) are elegant statistical machines. They don’t know facts — they know probabilities.
Each generated token reflects the likelihood of what might come next, drawn from billions of data points. Within this dance of probabilities lurks an ever-present flaw: hallucination.
An LLM hallucination is not a bug — it’s the consequence of probabilistic storytelling. Confident errors emerge when the model stitches together plausible phrases that are either logically inconsistent, factually inaccurate, or contradict external reality.
In mission-critical sectors like healthcare, law, finance, and national security, hallucinations represent catastrophic risks — from incorrect medical advice to fabricated legal precedents. This article goes beyond surface-level advice, offering a deep technical blueprint for understanding, measuring, and mitigating LLM hallucination in production AI systems.
What is Hallucination? Types and Definitions
Expanded Definition
Hallucination describes cases where an LLM:
- Generates confidently false content.
- Contradicts either explicit input context (intrinsic hallucination) or real-world knowledge (extrinsic hallucination).
- Fabricates non-existent entities, events, or sources.
| Type | Definition | Example |
|---|---|---|
| Intrinsic Hallucination | Contradicts the context provided in the prompt or document | In a medical summary, first states “patient has no allergies” then “patient allergic to penicillin”. |
| Extrinsic Hallucination | Contradicts factual world knowledge | “Marie Curie was awarded the Fields Medal.” |
| Fabricated Entities | Invents non-existent people, papers, laws, or organizations | “Professor Jane Eldwin of MIT discovered cold fusion in 2022.” |
| Overconfident Reasoning | Draws incorrect conclusions based on weak reasoning chains | “Since all primates fly, humans can fly.” |
Diagram — Cognitive Path to Hallucination
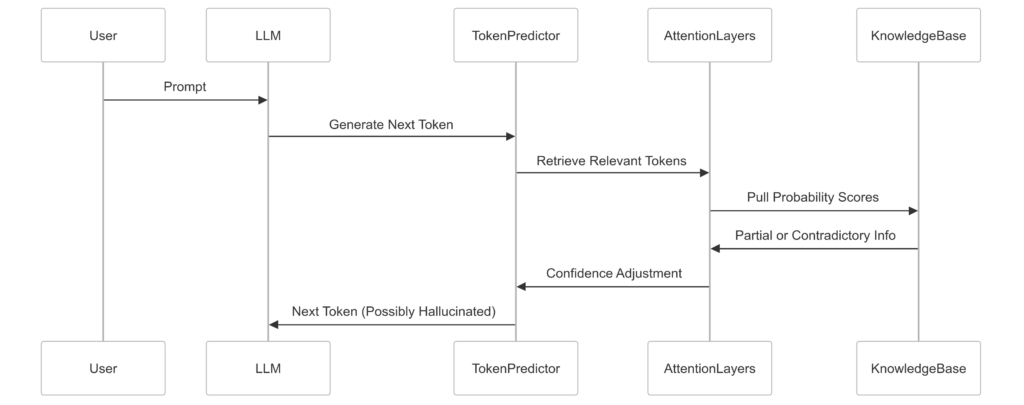
Structural Causes of Hallucination — Beyond “Missing World Models”
| Cause | Description |
|---|---|
| Token-by-Token Generation | Each token is generated in isolation, encouraging plausible flow over factual accuracy. |
| Contradictory Latent Knowledge | Training data embeds conflicting or outdated facts, confusing the prediction process. |
| Ambiguous Prompts | Poorly specified prompts force the LLM to “fill gaps” using likely but unverified content. |
| Lack of Epistemic Uncertainty | No explicit signal to distinguish “known facts” from “best guesses.” |
Example — Partial Uncertainty Handling (Hypothetical API)
response = model.generate(prompt, return_confidence=True)
print(response["text"])
print(f"Confidence: {response['confidence']}%")Detection Approaches — Comprehensive Framework
Table: Detection Techniques
| Approach | Description | Effectiveness |
|---|---|---|
| Self-Consistency | Ask the same question multiple times; check for stable answers. | Moderate |
| Retrieval-Augmented | Verify generated facts against external knowledge sources. | High |
| Contradiction Checks | Scan output for logical contradictions within the same response. | Moderate |
| Citation Validation | Require all factual claims to cite retrievable sources. | High |
Python — Contradiction Detection via Semantic Similarity
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-mpnet-base-v2')
def check_consistency(statements):
embeddings = model.encode(statements)
similarity = util.pytorch_cos_sim(embeddings[0], embeddings[1])
if similarity < 0.6:
print(f"Potential Contradiction Detected: {statements[0]} vs {statements[1]}")
check_consistency([
"The patient has no allergies.",
"The patient is allergic to penicillin."
])Building a Hallucination Test Harness
Purpose
A hallucination test harness wraps an LLM in a monitoring layer that:
- Tracks fact-checking rates.
- Detects self-contradictions.
- Scores citation quality.
- Monitors temporal drift.
Example Test Harness Architecture
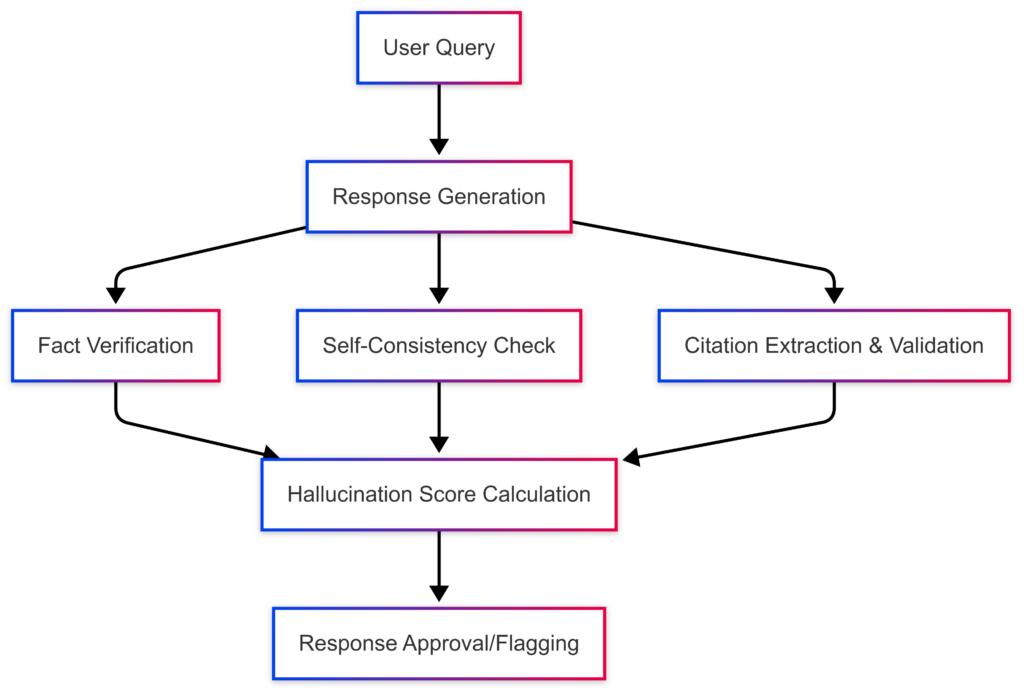
Reliability Metrics — Adding Quantified Accountability
| Metric | Description | Target |
|---|---|---|
| Hallucination Rate | % of responses containing hallucinations | <2% |
| Citation Completeness | % of factual claims with citations | >95% |
| Internal Consistency | % of non-contradictory responses | >98% |
| Confidence Calibration | Correlation between confidence & correctness | >0.90 |
Case Studies — Real Incidents & Lessons Learned
| Company | Incident | Technical Breakdown |
|---|---|---|
| HealthAI | Recommended non-existent drug. | Training corpus lacked recent FDA approvals. |
| LegalBot | Cited fake case law in legal memo. | Poor source attribution pipeline. |
| FinCorp | Generated conflicting regulatory advice. | Weak self-consistency checks. |
Deployment Strategies — Frameworks for High-Reliability Use Cases
| Use Case | Recommended Strategy |
|---|---|
| Customer Service | Self-consistency checks + retrieval-augmented generation (RAG). |
| Medical AI | Citation validation + domain-specific fine-tuning. |
| Financial Advice | Real-time regulator database integration. |
Diagram — Multi-Layer Hallucination Control Pipeline

Future Trends — Neuro-Symbolic Fusion and Beyond
| Trend | Description |
|---|---|
| Knowledge Graph Fusion | Embed entity relations directly in attention layers. |
| Epistemic Scoring | Add explicit “known vs guessed” markers to responses. |
| Self-Repair Loops | Model proposes corrections before user feedback. |
| Constitutional AI | Embeds self-critique as part of response generation. |
Conclusion — Balancing Creativity & Truth
Hallucination isn’t a bug; it’s the inevitable consequence of ungrounded creativity in probabilistic systems. The goal isn’t to eliminate creativity but to surround it with guardrails — balancing factual rigor with generative flexibility.
In the end, reliable AI isn’t about accuracy alone — it’s about knowing what you don’t know.
The post Beyond Hallucination: Measuring and Managing LLM Reliability in Production AI Systems appeared first on Adyog | Creative Design and Digital Product Development Company.